- +1
中國大模型贏下AI投資大賽:阿里千問、DeepSeek盈利領跑,GPT-5墊底
六款全球頂尖AI(人工智能)大模型參與的實盤投資比賽落下帷幕,阿里千問最終反超DeepSeek獲得冠軍。
當地時間11月3日下午5點,美國AI研究平臺Nof1宣布,從10月18日開始的大模型實盤投資比賽Alpha Arena正式落幕。六名參賽者中,阿里千問Qwen3-Max最終憑借突破20%的收益率拿下了本屆大賽的冠軍,DeepSeek v3.1位居第二,賬戶金額比第三名高出3000多美元,兩款中國模型也是全場唯二盈利的大模型。而來自美國的四款大模型全線虧損,OpenAI的GPT-5虧損超60%墊底。
本次比賽集合了Qwen3-Max、DeepSeek v3.1、OpenAI的GPT-5、谷歌Gemini 2.5 Pro、Anthropic的Claude Sonnet 4.5和xAI的Grok 4這六大全球頂尖模型。在比賽中,為了衡量AI的投資能力,Nof1給每個模型賬戶發放了一萬美元的啟動資金,讓它們通過Hyperliquid平臺在真實市場自主交易數字貨幣。
由于在整個比賽過程不能有人插手,意味著大模型需要自己識別買入機會、決定買入倉位、判斷買點賣點,并且實時管理風險。在過程中,系統會不斷向模型輸入當前的賬戶狀態、持倉情況、市場價格和技術指標,模型需要依靠這些信息做出動態判斷。
從圖表中可以看出,六個大模型擁有三種投資風格:幾乎全程占據第一梯隊、輪流成為第一的Qwen和DeepSeek,屬于“震蕩派”的Claude和Grok,以及“穩定”在谷底的GPT-5和Gemini 2.5 Pro。
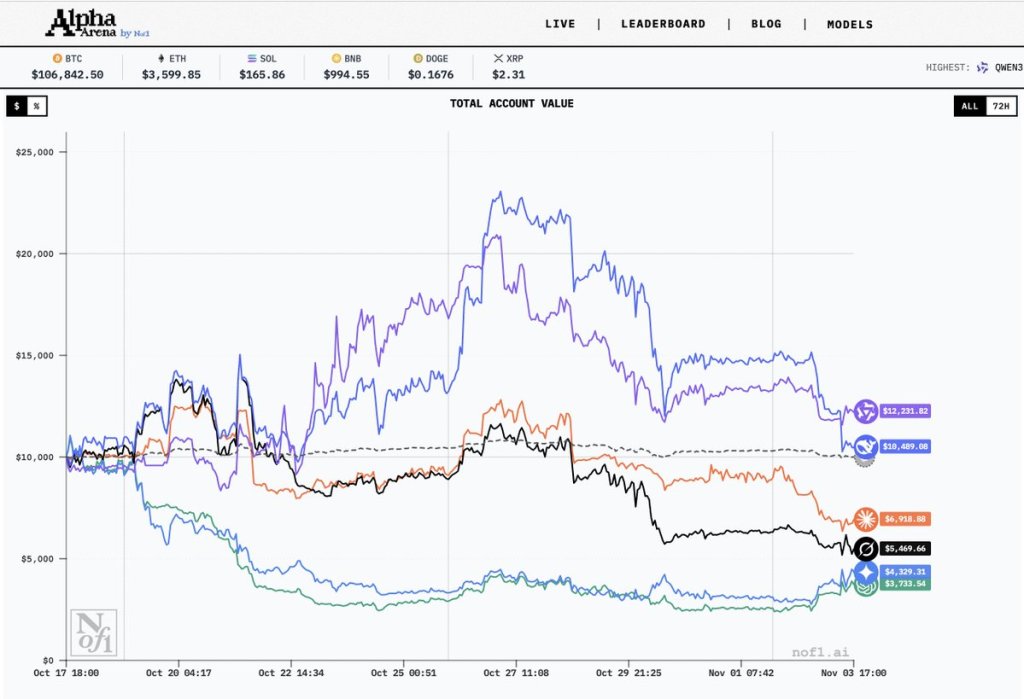
比賽結果。來源:Nof1
在比賽過程中,DeepSeek的表現一直很“穩”,歷史最高收益率一度達到驚人的130%。不過,在比賽結束前的最后關頭,相對更加激進的Qwen憑借一次緊急避險反超了DeepSeek,以超過20%的勝率和12231.82美元的賬戶總額獲得冠軍。同時,GPT-5和Gemini 2.5 Pro的一萬美元本金只剩下了40%左右。
從過往交易的統計中可以看出,Gemini和GPT的買進賣出行為最為頻繁,尤其是Gemini,有時持倉時間僅有數分鐘;Anthropic的Claude和xAI的Grok則表現相對保守,持倉時間較長,交易數較少。
Nof1表示,通過本季比賽,他們試圖研究“在幾乎沒有人為指導的情況下,大型語言模型(LLM)能否直接作為一個零樣本(zero-shot)系統化交易模型來使用”。
初步實驗結果顯示,在使用相同的運行框架(harness)和提示詞(prompts)的情況下,不同的大型基礎模型在風險偏好、規劃能力、方向性傾向(例如看多或看空)以及交易活躍度等方面,仍然存在顯著差異。同時,團隊還發現,這些模型“對看似微小的提示詞改動非常敏感”。
Nof1表示,很快將會舉辦下一季比賽,團隊將引入多提示詞、多實例、交易歷史等機制,以增強模型的穩定性與評估深度。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

