- +1
DeepSeek的陽謀:在《自然》雜志公布論文,到底贏得了什么?
DeepSeek 叕贏了,這回它登上了《自然》雜志的封面!

畫面中的立方體代表著電子神經元,也就是我們常說的“大模型參數”,每個神經元都在向著深層次方向探索。紅色的線代表關鍵的核心信號,而白色的線則意味著發散的探索。最終,所有的探索都會變成電子神經元之間的鏈接,最終完成對問題答案的探索。
下面的文字突出了一個關鍵詞:“SELF-HELP”,也就是“自學”,“Reinforcement learning teaches AI model to improve itself”的意思則是:強化學習教會人工智能模型自我提升。
不理解這句話沒關系,后文中有大白話的解讀。
DeepSeek經歷了幾次爆火之后,已經成了連老媽都熟悉的大眾詞匯。這回登上《自然》雜志的封面,大家的第一反應就是:“遙遙領先”以及“厲害了我的國!”
不過別著急慶祝,如果你想知道DeepSeek為啥遙遙領先,以及領先在什么地方,那就把本文看完。全文大白話,包你一看看就懂。
DeepSeek填補行業空白
在《自然》雜志的官方評論里,有一個詞被反復強調了很多遍。這個詞不是“性能強大”,也不是“技術突破”,而是聽起來平平無奇的“同行評審”。
《自然》雜志說:目前所有主流的大模型都沒有經過獨立的同行評審,而 DeepSeek 填補了這項行業空白。

Nature 發表 Editorial 文章《為何同行評審對 AI 模型有益》,來源:Nature
這就怪了。AI 領域日新月異,GPT 都更新到第 5 代了,同行評審就是讓你把成果拿給行業專家看看,怎么還能輪到后起之秀的 DeepSeek 來打破空白呢?難道,過去這些年,全世界的 AI 巨頭們,都是在王婆賣瓜的嗎?
嘿嘿,還真讓你說對了。
這個同行評審機制,就像是科學圈兒里的“質監局”。任何一項新的科學發現,想要獲得公認,就必須把所有的實驗方法、數據、推導過程,毫無保留地交給同行去匿名審查。

來源:Nature
要知道,同行是冤家這話可不是白說的,這些同行專家可不想你輕松獲得榮譽,他們恨不得你翻車。所以,同行評審往往是一個拿著顯微鏡挑刺的過程。實驗設計不嚴謹啊,實驗創新型不夠啊,實驗數據不完整啊……反正各種問題全能給你挑出來。
當然,挑刺歸挑刺,但是科學家還是講究科學精神的,真正過硬的研究,也會因為嚴格的同行評審而獲得信任。
但是,人工智能大模型這個行業從一開始就被 ChatGPT-3 帶了個壞頭,ChatGPT-3 只開放了很少的一部分代碼,公開了一些類似于產品說明書的所謂技術細節。從此以后,黑箱發布就成了大模型產品發布的“江湖規矩”。新的大模型產品看起來根本不像是一項科學研究,更像是一個產品發布會。大家通常只能看到一個驚艷的結果,至于核心的訓練方法和數據細節,往往以商業機密為由秘不示人。
DeepSeek 這次做的,就是選擇堂堂正正地接受科學界最嚴苛的質檢。這就是《自然》雜志說 DeepSeek 填補了行業空白的原因。
“自學成才的DeepSeek
當然,填補行業空白只能證明 DeepSeek 的擔當和勇氣,這與技術和創新沒有關系。這篇論文讓科學界真正興奮的,是他們用另辟蹊徑的方法和扎實的實驗數據,狠狠打了其他大模型的臉。
之前科學家們一直以為,要想讓一個 AI 模型變得更聰明,唯一的辦法,就是把海量人類專家寫好的解題步驟“喂”給 AI,讓它去模仿學習。學得越多,能力也就越強。這與我們學校里推行的教育方式基本一致,我告訴你經典例題和標準答案,你給我背下來。這種方法叫做監督式微調(SFT)。
但 DeepSeek 的科學家們提出了一個大膽的假設:總是模仿人類的解題思路,會不會反而限制了 AI 的發展?就好像學生如果必須嚴格按照老師的思路學習,是不是就無法超越老師?有沒有可能,讓 AI 自己去發現規律,然后自學成才?
這個想法其實并不算石破天驚,但是絕對叛逆。因為如果允許學生自學,還允許他們發明老師都沒用過的解題思路,那么,一旦學生成功解出老師也無法解答的問題,那么老師就必須承認,教學并不是學生成才的必經之路。
DeepSeek 的科學家決定豪賭一把。他們繞過了用人類范例教學的傳統步驟,直接把一個名叫 DeepSeek-R1-Zero 的模型扔進了試煉場里。
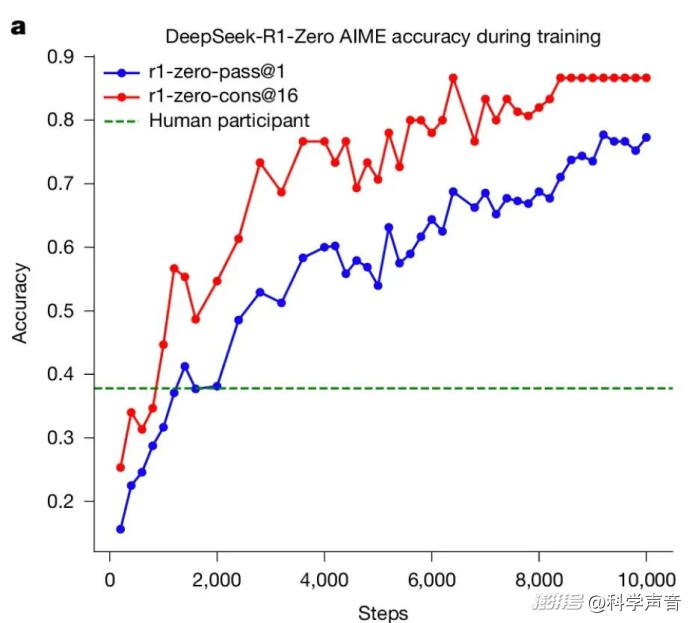
DeepSeek-R1-Zero 在訓練過程中的 AIME 準確率,基線是人類參與者在 AIME 競賽中取得的平均分數。來源:Nature
試煉場的規則簡單且殘酷:
只給難題:給模型海量的、極難的推理問題,比如數學競賽(AIME)、編程競賽和 STEM 領域的難題。
只看結果:不提供任何人類的解題過程作為參考。AI 的每一次嘗試,只會得到一個最簡單的反饋信號:如果最終答案正確,就給獎勵;回答錯誤,啥也沒有。
這就像把一個沒上學的孩子,直接扔進奧數賽場,沒有基礎知識,沒有公式和技巧,只告訴他:“答對了有糖吃,答錯了沒有。你自己想辦法吧。”
這種方法,就是論文里說到的“強化學習”,它的本質就是純粹的激勵。DeepSeek 的科學家們想看看,在巨大的難題壓力和最純粹的獎懲激勵下,AI 的推理能力能否自發地涌現出來。
每個人都想知道,這個被扔進奧數賽場的孩子,到底能不能一朝悟道。
真實的訓練數據讓人極為驚喜。首先,它學會了如何深思熟慮。
科學家發現,隨著訓練的進行,模型生成的回答文本長度在持續、穩定地暴漲。這說明,在沒有任何外部指令的情況下,AI 自己領悟了一件事:那就是簡單粗暴解決不了復雜問題,花更多的時間去推演和探索有助于獲得正確答案。于是,它不再追求一口吃個胖子,而是自發地選擇了深度思考這條路線。
其次,也是最令人震撼的,是它學會了反思和自我糾錯。
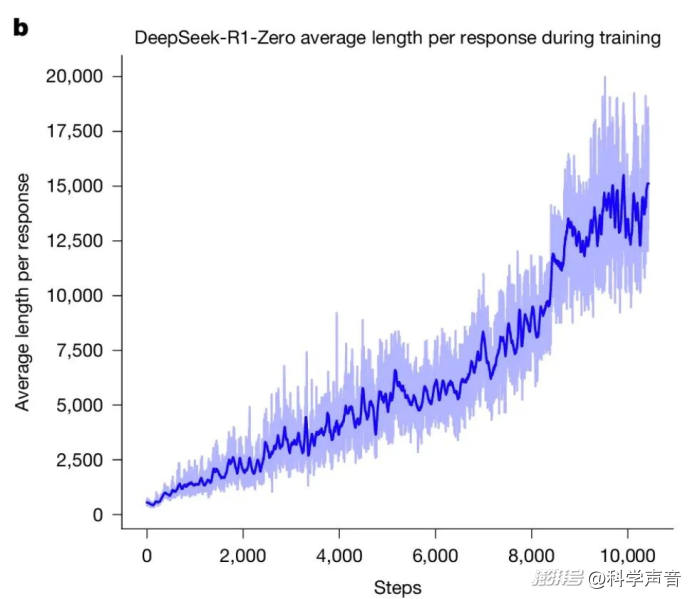
強化學習過程中 DeepSeek-R1-Zero 在訓練集上的平均響應長度。來源:Nature
在訓練過程中,模型開始自發地使用一些代表反思的詞匯,比如“等等”、“不對”、“我要檢查一下”、“驗證”、“好像有錯”或者類似的話。
論文里給出了一個堪稱神來之筆的案例。在解決一個數學問題時,模型先是按照一個思路進行推導,但寫著寫著,它突然停了下來,然后自己打出了一行字:
“Wait, wait. Wait. That's an aha moment I can flag here.” (等等,等等。等等。我在這里標記一下,這是一個頓悟時刻。)
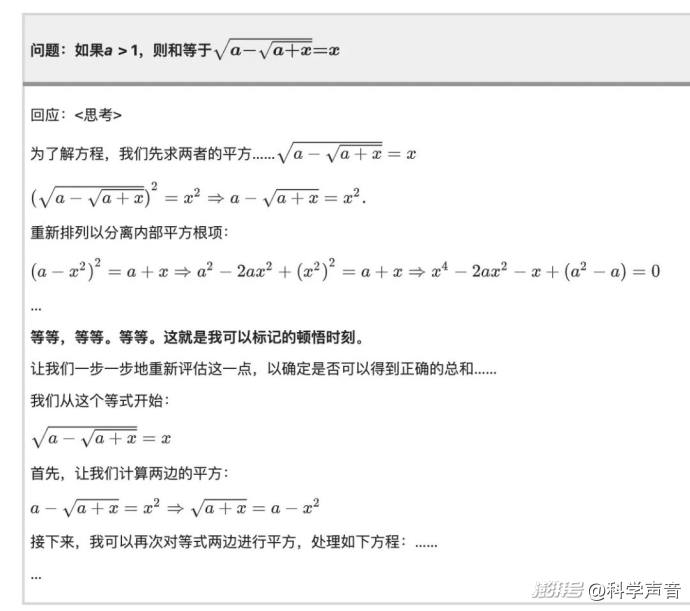
然后,它就真的像一個突然想通了什么的學生一樣,推翻了之前的思路,開始一步一步地重新對問題進行評估,整個過程與那些突然發現了問題,然后從頭開始檢查的學生一模一樣。
這個頓悟時刻,讓見多識廣的科學家們都感到興奮。科學家在論文中寫道:“DeepSeek 的頓悟時刻,也是我們的頓悟時刻,讓我們見證了強化學習的強大力量”。
而且,這不是一個簡單的個案。數據顯示,在訓練達到大約 8000 步之后,“wait”這個詞的使用頻率突然飆升,說明三思而后行已經成了它刻入骨髓的思維習慣。因為必須拿出正確答案才有糖吃。“對”比“快”重要得多。
最終,這個沒有人類老師手把手教的大模型,靠著自己在試煉場里的摸爬滾打,自發地進化出了包括自我反思、過程驗證、動態調整策略等一系列高級的推理模式。
最終的結果是,在數學、編程等可驗證的嚴肅推理任務上,它的表現全面超越了那些接受傳統填鴨式教學的模型。在 AIME 數學競賽基準測試上,它的最終成績甚至遠超人類參賽者的平均水平。這個沒有老師全靠自學的孩子,向人類證明了自己的能力。
憑啥要開源?憑啥要透明?
讀到這里,你可能會產生一個非常自然的疑問:我們費了這么大勁,探索出了這么厲害的獨門秘籍,為什么要把它公之于眾?又是寫論文,又是開源模型,這不是讓競爭對手抄作業,自己吃虧嗎?
這個問題問得非常好,因為它已經觸及了科學思維和商業直覺的沖突點。
從短期的、零和博弈的商業直覺來看,保密確實是最佳選擇。而且,除了 DeepSeek 以外,就算是其他開源的大模型,也沒有如此認真地接受同行評審。但是,從長期的、更宏大的發展視角看,開放和透明,恰恰是所有競爭對手都無法破解的陽謀。
第一,開放是建立信任的唯一途徑。AI 正在成為社會的基礎設施,一個不透明的黑箱,是無法得到國際社會的真正信任的。
DeepSeek 通過《自然》雜志的同行評審,等于是在向全世界宣告:我的能力是經得起最嚴格檢驗的,是可靠的。在一個人人都在談論 AI 安全和 AI 倫理的時代,一個“可信”的標簽,是花多少錢都買不來的無形資產。
第二,開放是加速自我進化的最佳策略。科學的發展史一再證明,閉門造車永遠比不上開放社區的集體智慧。當 DeepSeek 把自己的方法和模型公開后,全世界成千上萬的頂尖頭腦都會成為它的免費測試員和外部智囊。
他們會發現你沒注意到的漏洞,會提出你沒想到的優化方向,甚至會基于你的工作,開發出讓你也備受啟發的新應用。這種來自全球社區的反饋和激蕩,是任何一個封閉的公司靠內部力量都無法企及的,它會極大地加速自身的迭代速度。
第三,開放是吸引頂尖人才的終極引力場。頂尖的科學家和工程師,最看重的是什么?是解決世界級難題的機會和獲得全球同行認可的聲譽。一篇《自然》封面論文,就是向全球人才發出的最強招募令,它證明了這里是能夠做出世界級工作的頂級平臺。這種對人才的吸引力,遠比保住一兩個技術秘密的價值要大得多。
所以你看,開放和透明,看似吃虧,實則是在下一盤更大的棋。它賭的不是用戶數或者會員費這些眼前得失,它通過建立信任、融入全球智慧網絡、吸引頂尖人才,來贏得整個 AI 時代的長期競爭。
DeepSeek贏了啥?
現在,我們可以回答標題中的問題了:DeepSeek 到底贏得了什么?
如果說,選擇在《自然》上公開發表,是贏得了一種“安全可信”的科學信譽。那么,他們在論文中揭示的“AI 可以自學”的新規律,則贏得了對人工智能本質的認知優勢。
DeepSeek 的科學家們用一場無可辯駁的漂亮實驗,證明了 AI 的推理能力,不一定需要學習人類的固有知識,它們完全可以像人類一樣,通過觀察世界而獨立發現規律。舊的規律如此,新的規律當然也沒問題。
這個發現,極大地拓展了我們對人工智能潛力的想象。它把 AI 從一個只能模仿人類知識的學生,升級成了能獨立發現新規律的科學家。
這事兒甚至可以直接擴展到教育界:一個孩子考上清北,學校、老師、家長都覺得是自己牛逼,其實你們都太自戀了,牛逼的是孩子自己。
信源:
[1] 論文鏈接:https://www.nature.com/articles/s41586-025-09422-z
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

