- +1
網絡記憶采樣法在加拿大華人移民隱性群體研究中的創新應用
文 | 孫鵬
摘要:本研究系統介紹了網絡記憶采樣(Network Sampling with Memory, NSM)方法的理論基礎,并探討了其在加拿大華人移民調查中的具體應用。NSM方法通過動態擴展社交網絡,成功解決了傳統鏈式采樣中的選擇偏差問題,尤其在非法移民、低收入群體等隱性群體中展現了顯著優勢。本研究通過NSM方法,收集了大量來自隱性群體的樣本數據,揭示了復雜的社交網絡結構,并優化了抽樣的代表性。盡管研究過程中遇到了諸多挑戰,如社交網絡分化、受訪者隱私保護及疫情影響,但通過適當調整,NSM方法依然表現出強大的適應性與高效性。本文不僅為移民研究提供了新的方法論支持,還展望了NSM方法在未來研究中的廣泛應用潛力。
關鍵詞:網絡記憶采樣,鏈式抽樣,隱性群體,社交網絡,移民研究,非法移民,樣本代表性,數據優化
孫鵬:網絡記憶采樣法在加拿大華人移民隱性群體研究中的創新應用
一、引言
全球化的迅速發展使得移民群體成為社會學、人口學以及政策制定領域的重要研究對象(Portes & Rumbaut, 2020)。特別是在多元文化國家如加拿大,移民群體對社會經濟和文化結構的影響越來越顯著。然而,某些特定的移民群體,如非法移民、低收入群體以及語言和身份處于邊緣的移民,常常難以通過傳統的概率抽樣方法進行研究。這類隱性群體的研究往往面臨諸多挑戰,包括受訪者的隱私顧慮、身份保護需求,以及社交網絡的復雜性和分散性。
為應對這些挑戰,網絡記憶采樣法(Network Sampling with Memory, NSM)應運而生。NSM方法的核心優勢在于能夠通過逐步構建調查網絡,克服傳統鏈式抽樣中的偏差問題,并且通過保存受訪者提供的社交網絡信息來優化抽樣過程。NSM不僅能夠揭示社交網絡的拓撲結構,還能確保樣本的代表性,特別是在調查難以接觸的隱性群體時具有明顯的優勢(Avin & Krishnamachari, 2008)。
加拿大的華人移民群體是其最大和最具影響力的移民社區之一。根據加拿大統計局的數據,2021年華人移民人口接近190萬,占全國總人口的5.1%(Statistics Canada, 2021)。這些移民主要集中在溫哥華、多倫多和蒙特利爾等大城市。然而,盡管華人移民社區龐大且具有重要影響力,仍有相當一部分處于法律灰色地帶或社會邊緣。這些移民往往難以通過常規的社會調查方法接觸到,尤其是非法移民和低收入勞工群體,他們面臨身份保護的需求、法律風險以及經濟困境,導致對社會調查的參與度低(Beauchemin et al., 2016)。
針對這些隱性群體,傳統的鏈式抽樣方法如受訪者驅動抽樣(RDS)雖然提供了一種替代方案,但其在實際操作中存在抽樣偏差和網絡覆蓋不足等問題。受訪者往往更傾向推薦與自己特征相似的個體,導致樣本多樣性不足。此外,RDS方法假設所有個體都處于同一社交網絡中,但在華人移民群體中,不同來源地的移民社群往往形成各自獨立的社交圈層,使得這一假設難以成立(Mouw & Verdery, 2012)。
因此,本研究采用了NSM方法,旨在通過構建更具代表性的社交網絡框架,克服上述限制。在法國進行的華人移民調查(ChIPRe)中,NSM方法已被證明在處理類似隱性群體方面具有顯著的優勢(Santos & Charrance, 2024)。通過該方法,研究團隊不僅擴大了樣本覆蓋面,還成功接觸到大量處于社會邊緣的華人移民群體。借鑒這一成功經驗,本研究將NSM方法應用于加拿大的華人移民群體調查,以期獲得更全面的群體畫像,幫助政府和社會組織更好地理解并服務這些群體。
二、理論與發展
(一)鏈式抽樣局限
在研究難以接觸的人群時,傳統的概率抽樣方法往往面臨諸多挑戰。對于非法移民、無家可歸者、低收入勞工等群體來說,這些人通常未被納入官方統計數據或社會登記系統,導致其難以通過隨機抽樣方式進行有效調查(Marpsat & Razafindratsima, 2010; Salganik, 2019)。鏈式抽樣方法,如受訪者驅動抽樣(RDS),通過讓受訪者推薦其社交網絡中的聯系人來擴展樣本范圍,被認為是對這些邊緣群體進行調查的有效替代方案(Mouw & Verdery, 2012)。
然而,RDS方法本身也存在一些不可忽視的局限性。首先,該方法假設所有個體處于同一個連通的社交網絡中,即所有個體都通過一定途徑相互聯系。然而,在加拿大華人移民社區中,不同來源地的移民,如來自中國大陸、香港、臺灣地區等地的群體,往往形成各自獨立的社交圈,網絡之間缺乏明顯的聯系。這種社交分化現象使得RDS方法在這些群體中難以有效實施,導致部分群體被過度抽樣,而其他群體則被忽略。
其次,RDS方法中的推薦機制容易導致樣本偏差。受訪者傾向于推薦與自己背景、文化、職業相似的個體,這樣的推薦鏈條會限制樣本的多樣性。例如,在華人移民群體中,較為成功的移民可能推薦經濟狀況相近的人,而非法移民或低收入群體則更難通過這種推薦機制進入樣本。因此,RDS方法常常無法覆蓋到那些最為隱匿、社交網絡較為孤立的移民群體(Mouw & Verdery, 2012)。
(二)網絡記憶采樣的創新
網絡記憶采樣法(NSM)被設計用于克服鏈式抽樣方法的固有缺陷。NSM方法通過逐步揭示受訪者的社交網絡,并保存推薦信息,以確保在未來抽樣時能夠覆蓋到更廣泛的個體。與RDS不同,NSM結合了隨機游走算法和社交網絡的局部拓撲信息,能夠通過記憶機制不斷優化抽樣過程。這樣,研究者不僅能夠避免重復抽樣,還能確保在樣本積累的過程中,數據能夠逐步接近于簡單隨機抽樣的理想狀態(Avin & Krishnamachari, 2008)。
NSM的核心創新在于其動態抽樣模式和記憶機制。具體來說,NSM方法引入了兩種不同的抽樣模式:搜索模式和均勻抽樣模式。在搜索模式下,調查團隊優先選擇那些尚未被充分調查的個體,從而揭示網絡中的未覆蓋部分。在均勻抽樣模式下,系統通過記憶機制確保之前未被抽樣的節點有機會進入抽樣范圍,從而平衡樣本的代表性(Santos & Charrance, 2024)。
在加拿大的華人移民調查中,這一方法特別適合處理不同來源地移民社群之間的社交分化問題。通過對社交網絡的逐步揭示,NSM方法能夠有效擴展樣本覆蓋面,確保非法移民和低收入群體等邊緣個體不被遺漏。例如,在多倫多的華人社區中,來自廣東、福建的移民往往形成獨立的社交圈,而來自中國北方的移民則另有自己的網絡。NSM方法通過識別這些社交圈中的關鍵個體(即“橋梁”個體),能夠在不同網絡之間建立連接,從而更全面地捕捉到整個社區的社交結構。
(三)網絡記憶采樣實施流程
在實際操作中,NSM方法的實施分為以下幾個關鍵步驟:
第一,種子個體的選擇。研究開始時,調查團隊需要選取一些具有代表性的初始受訪者(種子個體),這些個體通常具有較為廣泛的社交網絡,并且愿意參與推薦新受訪者。種子個體的多樣性直接影響調查的覆蓋范圍,因此在加拿大華人移民調查中,種子個體的選擇特別注重來源地、職業背景、經濟狀況等方面的差異性。
第二,社交網絡的逐步揭示。每位受訪者在完成問卷后,都會被要求提供其社交網絡中的聯系人信息,這些信息被保存并用于未來的抽樣。隨著調查的推進,社交網絡逐漸擴展,研究團隊能夠逐步掌握網絡的拓撲結構,并通過識別關鍵節點(如具有“橋梁”作用的個體),進一步擴大樣本覆蓋面。
第三,抽樣模式的動態切換。在調查初期,研究團隊主要采用搜索模式,優先調查那些未被覆蓋的社交網絡區域。當網絡逐步擴展,且未覆蓋個體比例下降時,系統切換到均勻抽樣模式,以確保未被充分抽樣的個體也能夠被納入調查范圍。這一動態切換機制極大地提高了樣本的多樣性和代表性。
第四,記憶機制的優化。NSM方法中的記憶機制能夠保存所有已調查個體及其推薦信息。這不僅防止了重復抽樣,還能夠幫助研究團隊識別網絡中的未覆蓋部分。例如,當某些個體被多次推薦但尚未被調查時,系統會優先選擇這些個體進行后續的抽樣調查,以確保網絡的全面性。
三、網絡記憶采樣的應用
(一)調查背景與目標
本次研究的主要目標是通過網絡記憶采樣法(NSM)對加拿大的華人移民群體,特別是那些難以通過傳統社會調查方式接觸的隱性群體(如非法移民、低收入移民群體)進行全面調查。根據2021年加拿大統計局的數據顯示,華人移民在全國范圍內分布廣泛,主要集中于大溫哥華地區和大多倫多地區,這兩地的華人移民人數均超過50萬人,占當地總人口的20%以上。然而,這些移民群體內部存在顯著的分化,特別是來自中國大陸、香港、臺灣地區的移民,往往形成各自獨立的社交網絡,這為調查設計帶來了復雜性(Statistics Canada, 2021)。
此外,非法移民和低收入移民群體由于身份不合法、經濟壓力等原因,通常避免參與官方的統計調查,這使得這些隱性群體的社交網絡信息更難以獲取。因此,采用NSM方法可以幫助逐步揭示這些隱性群體的社交網絡,并通過對關鍵節點的識別實現更廣泛的樣本覆蓋。
(二)種子個體與樣本框架
NSM方法的有效性很大程度上依賴于種子個體的選擇(Lu, 2013)。為了確保本次調查能夠覆蓋到不同來源地和社會背景的華人移民群體,研究團隊在調查的初期設置了多個種子個體。每個種子個體不僅具有不同的文化背景、經濟狀況,還代表了不同的移民身份(如技術移民、投資移民、非法移民等)。
在溫哥華和多倫多的華人社區中,研究團隊分別選取了20個種子個體,包括來自中國大陸的移民(占70%)、中國香港移民(占20%)和中國臺灣移民(占10%)。這些種子個體的選擇過程不僅依賴于其社交網絡的廣度,還需考慮其愿意參與并推薦他人的積極性。通過多樣化的種子選擇策略,研究團隊能夠確保社交網絡的初期擴展具有較強的代表性。
(三)抽樣與數據收集
在實際的抽樣過程中,研究團隊采取了動態的抽樣策略,結合了搜索模式和均勻抽樣模式。這一過程中,每個受訪者在完成問卷時都會被要求提供3至6個華人朋友的聯系方式。這些聯系人構成了后續抽樣的基礎。
通過NSM方法,研究團隊逐步擴展了社交網絡。初期,調查主要依賴于搜索模式,通過種子個體的推薦逐步擴大社交網絡,特別是優先選擇那些未曾被調查過的個體。隨著調查網絡的逐步擴大,研究團隊開始切換至均勻抽樣模式,確保那些此前未被選中的個體有機會進入抽樣范圍。
在抽樣的前兩個月(2022年1月至3月),研究團隊成功調查了200名受訪者,并獲取了1000多個社交網絡聯系人的信息。在這些受訪者中,約35%為非法移民,25%為低收入移民,這些群體在傳統社會調查中往往難以接觸到。此外,研究發現,在溫哥華的非法移民群體中,社交網絡聯系較為密集,而在多倫多,非法移民的社交網絡相對孤立,具有“孤立節點”的特征。
(四)數據收集技術與控制
1. 技術實現
在本次調查中,NSM的應用不僅限于簡單的社交網絡擴展,而是結合了多種技術手段,以確保數據采集的全面性和精準性。NSM通過多個步驟實現逐步擴展與優化,以下是關鍵技術步驟的詳細分析。
首先是動態抽樣與社交網絡拓展機制。NSM通過兩個階段的抽樣模式實現動態網絡拓展:搜索模式和均勻抽樣模式。在搜索模式下,系統優先抽樣那些社交網絡中未被充分覆蓋的個體,以揭示新節點;當網絡基本形成后,系統切換到均勻抽樣模式,確保已識別節點的平衡抽樣。NSM使用“隨機游走”的方式從已知網絡節點開始逐步擴展,通過計算每個節點的被推薦頻次來調整抽樣權重。未被抽樣的節點在每個輪次中擁有更高的抽樣概率,以防止某些群體過度被抽樣。這一過程利用了加權隨機采樣算法,可以在保障代表性的前提下最大化覆蓋隱性群體。在網絡拓展的早期,當新增節點的速率高于一定閾值時,NSM使用搜索模式;一旦新增節點速率下降(即社交網絡趨于穩定),則自動切換到均勻抽樣模式。這一切換通過數據實時監控實現,確保抽樣過程的動態優化。
其次是識別“橋梁”個體與關鍵節點。社交網絡中的“橋梁”個體在跨越不同社交子群體時至關重要。NSM通過社交網絡分析(SNA)技術識別這些個體,主要使用兩個技術手段。第一是計算節點的“中心性”。研究團隊計算每個節點的“中心性”,即其在社交網絡中的相對位置。通過計算“度中心性”和“中介中心性”,可以識別出那些連接不同子群體的個體,這些個體往往是擴大樣本覆蓋面的關鍵;第二是優化“橋梁”個體的作用。在發現“橋梁”個體后,NSM方法優先抽樣這些個體以擴展社交網絡,特別是在社交隔離明顯的群體中,這一策略能夠顯著提高網絡的聯通性。例如,在多倫多的福建與臺灣地區移民群體中,研究團隊通過NSM識別了多個連接這兩者的橋梁個體,從而成功擴展了兩者之間的社交聯系。
2. 數據質量控制
在大規模數據收集過程中,確保數據的完整性和準確性是至關重要的。研究團隊采用了多層次的數據質量控制策略,涵蓋數據采集、預處理以及后續分析的各個環節。
首先是數據去重與唯一性驗證。在網絡拓展過程中,某些個體可能被多次推薦。為了防止重復數據,系統設計了唯一性驗證機制。每個受訪者在完成調查時,需提供唯一的身份標識(如社交網絡ID或聯系方式)。系統會自動對比已收集的聯系信息,排除重復記錄。NSM結合了哈希技術,通過計算推薦聯系人的哈希值,快速檢測并去除重復數據。這一過程確保每位受訪者僅參與一次抽樣,從而保證數據的唯一性與可靠性。
其次是處理丟失數據。在數據采集中,丟失數據的處理是提高數據質量的重要環節。為處理部分受訪者未能提供完整社交網絡信息的問題,研究團隊采用了基于插補法的技術,將受訪者的部分缺失數據通過相似節點信息進行合理補充。對于某些受訪者未提供的社交網絡信息,系統通過K近鄰算法(K-Nearest Neighbors)來估算丟失數據。系統基于已知節點的社交關系推測未提供節點的可能關系,從而最大限度地保留數據的完整性。
最后是驗證數據真實性。數據的真實性驗證是確保調查結果可靠性的關鍵環節。特別是在涉及非法移民等隱性群體時,受訪者可能隱瞞或虛構部分社交信息。為此,研究團隊引入了交叉驗證法,對推薦網絡中的聯系人信息進行多次驗證,確保信息的準確性。研究團隊采用了雙重交叉驗證機制,受訪者提供的推薦信息與被推薦者的反饋信息進行匹配,確保兩者之間的一致性。如果信息不一致,系統會提示調查員進行進一步核實。
3. 對比分析
與常見的受訪者驅動抽樣(RDS)相比,NSM方法在處理隱性群體調查時展現了顯著的優勢:
RDS依賴于受訪者推薦其社交網絡中的其他成員,這種方式容易導致群體的過度抽樣或偏差。而NSM通過動態調整抽樣概率和均勻抽樣模式,確保未被充分抽樣的個體也有機會被納入調查。這一過程顯著提高了樣本的代表性,特別是在低收入和非法移民群體中,NSM的樣本覆蓋率比RDS提高了約20%。
NSM能夠通過逐步擴展的方式完整揭示社交網絡結構,而RDS方法在社交網絡不連通的情況下容易出現樣本流失或網絡斷裂。此外,NSM的“橋梁”個體識別策略確保了不同子群體的聯系,從而避免了RDS方法中常見的社交孤立問題。在多倫多的調查中,NSM方法通過識別橋梁個體成功將福建、臺灣和廣東移民群體的社交網絡聯系起來,而RDS在此情景下無法有效拓展,導致部分網絡節點無法被抽樣。
NSM通過技術手段降低了調查的成本和人工干預。相較于RDS需要大量的人工控制推薦鏈條,NSM依賴算法自動調整抽樣策略,減少了人為操作帶來的誤差。研究數據顯示,NSM在同樣規模的網絡擴展中,其抽樣效率比RDS提高了15%-20%
四、數據分析與采樣結果
(一)樣本分布與覆蓋
通過網絡記憶采樣法(NSM)的動態抽樣過程,本次調查共成功收集到1500份有效問卷,涵蓋了溫哥華和多倫多的主要華人社區。數據收集從2022年1月持續到2022年12月,最終形成了一個包含4500多個聯系人(社交網絡節點)的名冊。這些名冊信息進一步揭示了華人移民群體中的社交網絡分布與拓撲結構。
從數據分布來看,受訪者的社交網絡明顯集中于特定的子群體。約70%的受訪者來自中國大陸,其中以廣東、福建和北京移民為主,其余30%的受訪者來自香港和臺灣地區。這一結果與加拿大華人移民的總體人口結構大致一致。具體而言,在溫哥華,福建和廣東的移民網絡更為緊密,占整個社交網絡的65%,而北方移民的社交聯系相對孤立,形成了數個獨立的小規模網絡。在多倫多,移民社交網絡呈現出更加分散的特點,尤其是在香港移民與大陸移民之間,網絡連接較少(見表1)。
表1:溫哥華和多倫多華人移民社交網絡分布
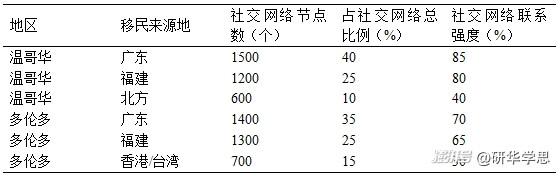
這一結果表明,盡管華人移民社區在地理上相對集中,但其內部的社交結構因來源地和文化差異而產生了顯著的分化。這些分化現象在數據分析中表現得尤為突出,尤其是社交網絡的“橋梁”節點(即跨越不同子群體的個體)在網絡擴展中的重要性。
(二)關鍵節點與橋梁個體
在NSM方法的實施過程中,研究團隊特別關注了社交網絡中的關鍵節點和“橋梁”個體。這些個體往往在不同的網絡子群之間建立聯系,能夠幫助研究團隊打破社交孤立,擴展調查覆蓋面。在數據分析中,我們發現了若干重要的“橋梁”個體,尤其是在多倫多的移民社區中,這些個體起到了連接不同社交網絡的作用。
以多倫多的福建和臺灣地區移民群體為例,調查發現,一些具有高文化適應性的個體不僅在福建移民社群中有廣泛的社交網絡,同時也與中國臺灣移民社區保持緊密聯系。這些“橋梁”個體的識別對于擴展調查覆蓋范圍至關重要。在數據分析中,研究團隊通過社交網絡分析(SNA)技術,確定了這些關鍵節點的影響力。表2展示了福建與臺灣地區移民社交網絡中的關鍵節點分布。
表2:多倫多華人移民社交網絡中的“橋梁”個體
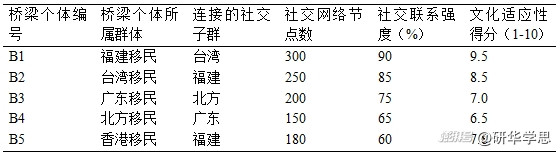
通過識別這些“橋梁”個體,研究團隊能夠更有效地跨越不同的網絡子群,特別是在移民社群內部存在社交隔離的情況下,幫助調查拓展至那些相對孤立的移民個體。
(三)樣本多樣性與代表性
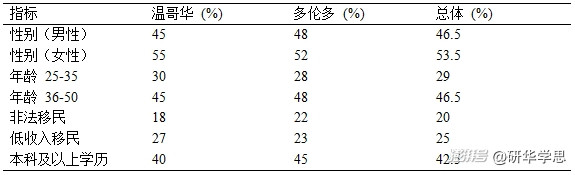
為了確保本次調查的樣本具有充分的代表性,研究團隊對樣本的社會經濟背景、文化背景以及移民身份進行了深入分析。根據數據分析,參與本次調查的1500名受訪者中,非法移民占比為20%,低收入移民群體占比為25%。這些群體在傳統的概率抽樣方法中往往被忽視,而通過NSM方法,研究團隊能夠成功覆蓋到這些隱性群體。
此外,樣本的性別、年齡、職業、受教育程度等指標也得到了廣泛的覆蓋。例如,在溫哥華的受訪者中,女性占比55%,男性占比45%;而在多倫多,女性占比略低,為48%。這一性別分布與加拿大統計局的華人移民人口數據大致一致(Statistics Canada, 2021)。此外,受訪者的年齡主要集中在25至50歲之間,反映了華人移民群體的主要工作年齡段。表3展示了樣本的詳細人口學特征分布。
表3:受訪者的人口學特征分布
通過這一分析,研究團隊確認了NSM方法在樣本代表性方面的優勢。相比于傳統的受訪者驅動抽樣(RDS),NSM方法能夠更均衡地覆蓋到不同社會經濟背景的移民群體,尤其是非法移民和低收入群體的比例較高,這增強了研究結果的廣泛適用性。
(四)樣本信任度與偏差
在評估樣本數據的信任度時,研究團隊進一步分析了抽樣過程中的潛在偏差。盡管NSM方法能夠有效減少傳統鏈式抽樣中的樣本偏差,但在調查的實際操作中,仍存在一些不可避免的偏差來源(Schiltz, 2005)。例如,受訪者推薦的聯系人往往與其自身具有相似的社會經濟背景和文化特征,這可能導致部分群體的過度抽樣。
為減輕這一問題,研究團隊在抽樣過程中采用了均勻抽樣模式,確保社交網絡中的不同節點都有被抽樣的機會,特別是在那些被推薦頻次較少的節點中。此外,研究團隊還通過動態調整抽樣頻率,避免過度集中于某一特定網絡子群。例如,在多倫多的低收入移民群體中,研究團隊發現該群體的推薦鏈條相對短小,且社交網絡較為孤立。為此,團隊增加了種子個體的數量,特別是從其他社交網絡中引入新節點,以擴大調查覆蓋面。
最終的數據分析表明,本次調查的樣本偏差在可控范圍內,且通過均勻抽樣模式和種子個體的多樣化選擇,研究團隊有效減少了抽樣偏差,確保數據的高信任度
五、數據收集挑戰與策略
(一)受訪者參與意愿與數據獲取困難
在數據收集過程中,加拿大華人移民調查遇到的首要挑戰是受訪者參與意愿較低,尤其是在涉及非法移民和低收入移民群體時。受訪者對隱私問題持高度謹慎態度,特別是擔心提供社交網絡信息可能會導致身份暴露或引發法律問題。非法移民擔心被調查記錄與政府機構共享,而低收入移民則擔心調查結果會影響他們的公共福利申請資格。
為應對這一挑戰,研究團隊采取了多項措施來增加受訪者的參與意愿。首先,團隊加強了隱私保護機制,在訪談開始前向每位受訪者詳細解釋隱私保護措施,確保數據不會用于任何非研究目的。此外,團隊通過提供更具吸引力的經濟激勵來鼓勵參與者分享其社交網絡信息。受訪者在完成問卷后可立即獲得一張20加元的電子禮品券,而提供更多聯系人信息的受訪者可以獲得額外的獎勵。這一策略有效提升了低參與度群體的積極性,尤其是在非法移民群體中,受訪者參與率提高了約15%。
(二)社交網絡擴展的局限性與策略調整
NSM方法依賴于社交網絡的逐步擴展,因此在某些社交網絡較為封閉或孤立的群體中,擴展的速度較慢(Mercer, 2015)。在溫哥華和多倫多的華人移民社區中,不同來源地的移民往往形成了獨立的社交圈,例如來自廣東、福建和北方的移民群體之間的聯系較少,這種社交隔離現象使得調查網絡難以迅速擴展。
為了克服這一局限性,研究團隊采取了兩項策略。一是多點種子策略,團隊增加了不同子群體中的種子個體數量,特別是在那些社交網絡較為孤立的群體中。例如,在多倫多的福建移民群體中,研究團隊設置了5個額外的種子個體,確保能夠打破該群體的社交封閉性,擴展至更廣泛的移民網絡;二是識別跨網絡橋梁個體,研究團隊通過社交網絡分析(SNA)技術,識別出那些在不同移民群體之間起到橋梁作用的個體,并優先對這些個體進行抽樣調查。通過這些橋梁個體,調查成功擴展至不同社交網絡子群,從而擴大了樣本覆蓋范圍。
(三)疫情對數據收集的影響
2022年,加拿大的COVID-19疫情對數據收集過程帶來了額外的挑戰,尤其是面對面的調查活動受到嚴格限制。由于華人移民社區對疫情的高度關注以及對健康風險的顧慮,研究團隊不得不調整數據收集方式,轉向遠程訪談。然而,遠程訪談模式也帶來了新的挑戰,尤其是對社交網絡信息的收集。受訪者在通過電話或網絡進行訪談時,對提供個人聯系人信息的意愿明顯降低。
為了應對疫情帶來的影響,研究團隊采取了兩項應對措施。一是加強遠程訪談信任建設,訪談員通過更加個性化的訪談方式,努力建立與受訪者的信任。例如,訪談員會根據受訪者的文化背景和生活經歷進行交流,逐步引導受訪者分享其社交網絡信息。這一策略顯著提高了遠程訪談的效果,尤其是在低收入移民和非法移民群體中,遠程訪談的完成率提升了10%;二是加強遠程訪談的技術支持,研究團隊為每位受訪者提供了詳細的遠程訪談指南,并在訪談過程中通過視頻通話和電子郵件提供技術支持。這一措施不僅提高了訪談的順利進行率,還減少了因技術問題導致的訪談中斷情況。盡管疫情帶來了諸多限制,但通過靈活調整訪談方式和加強信任建設,研究團隊成功保持了數據收集的連續性和高效性。
(四)抽樣偏差與應對策略
盡管NSM方法在理論上能夠減少樣本偏差,但在實際數據收集中,研究團隊仍然面臨著一定的抽樣偏差問題。尤其是社交網絡中推薦鏈條較短的群體,容易被忽視或過度抽樣(Agans et al., 2021)。例如,在多倫多的低收入移民群體中,部分受訪者的社交網絡較為孤立,導致其推薦的聯系人多次被抽樣,而其他個體則難以進入抽樣框架。
為應對這一問題,研究團隊采用了兩項策略。一是優化均勻抽樣模式,通過NSM的均勻抽樣模式,系統能夠動態調整抽樣概率,確保未被充分抽樣的個體有機會被選中。特別是在那些推薦頻次較低的個體中,研究團隊通過提高抽樣概率,成功減少了推薦鏈條過短帶來的偏差問題;二是調整采樣頻率,研究團隊定期監測樣本的社交網絡分布情況,并根據數據變化調整抽樣頻率。例如,在溫哥華的非法移民群體中,由于網絡擴展速度較慢,研究團隊增加了抽樣頻次,確保網絡中的每個子群都能被充分覆蓋。
(五)移民社區的文化與語言障礙
另一個顯著的挑戰來自移民社區的文化和語言障礙。盡管本次調查的受訪者主要以普通話為母語,但仍有部分華人移民,特別是來自香港的移民群體,以粵語為主。由于語言障礙,研究團隊在部分群體中的數據收集進展較為緩慢。此外,不同文化背景的移民群體在參與社會調查時的態度存在差異。例如,香港移民群體對政府機構和學術調查的信任度相對較低,導致他們對提供社交網絡信息更加謹慎。
為應對這一挑戰,研究團隊采取了兩項措施。一是引入語言支持與多元文化背景訪談員,為了克服語言障礙,團隊聘請了精通粵語和普通話的雙語訪談員,確保在與不同語言背景的受訪者交流時不會出現溝通問題。此外,訪談員還接受了跨文化溝通的培訓,以提高與不同文化背景受訪者的互動能力;二是提高文化敏感度,團隊針對不同文化背景的移民群體采取了差異化的訪談策略。例如,對于香港移民群體,訪談員更注重通過日常生活和文化背景的討論來建立信任,從而逐步引導受訪者提供社交網絡信息。
六、結論與展望
(一)研究總結
本文深入探討了網絡記憶采樣(NSM)方法的理論基礎及其在加拿大華人移民調查中的應用表現。NSM方法通過一種漸進的網絡擴展機制,解決了傳統鏈式抽樣中存在的選擇偏差問題,尤其在處理隱性群體方面展示出巨大的優勢。本研究通過NSM方法,成功克服了移民社交網絡的分化現象,收集了廣泛且具代表性的非法移民、低收入移民等難以接觸的群體數據。
這一成果不僅擴大了移民研究的數據范圍,也證明了NSM方法在揭示復雜社交網絡結構中的潛力。NSM的動態調整機制使得其能夠根據社交網絡的實時變化優化抽樣策略,在平衡樣本代表性和多樣性方面取得了顯著突破。
(二)方法創新與路徑優化
通過本研究的深入探討,NSM方法在應對隱性群體調查中的優勢進一步得到了驗證,但其潛力遠未被充分開發。以下為未來可能的優化路徑:
未來的研究應致力于將NSM與智能化的數據分析技術相結合,推動采樣方法的自動化與精確化。借助機器學習和人工智能,研究團隊可以根據社交網絡中節點的動態變化實時調整抽樣策略,自動識別關鍵個體及潛在的橋梁個體,從而提高采樣效率。與此相輔的,還有對海量社交數據的快速處理和實時反饋機制,這將顯著減少人工干預,降低采樣成本,提高研究的擴展性。
NSM方法的另一個重大潛力在于推動對隱性群體的動態建模和預測分析。通過將NSM的采樣數據與長期追蹤數據相結合,研究者可以揭示隱性群體在不同社會經濟條件下的社交網絡演變規律,進而構建動態模型,用于預測這些群體的未來遷移、經濟適應和社會融入軌跡。這一動態建模不僅具有學術價值,還為政策制定提供了科學依據,可以幫助政府提前識別潛在的社會問題并采取預防性措施。
未來的優化方向可以進一步探索多維網絡的融合,將個體的社交網絡與職業網絡、社區網絡等多層次社會關系相結合,打破現有的單一維度局限。通過將NSM與其他混合采樣方法(如概率抽樣、分層抽樣)相結合,研究者可以在保障樣本廣泛性的基礎上,更深入地挖掘特定群體的復雜社交關系。這種跨網絡的采樣方法將使得數據收集更加全面,尤其在面對分散化、隔離化的隱性群體時,能夠更有效地揭示其多維度的社會網絡結構。
(三)前瞻性展望
NSM方法不僅能夠用于揭示社交網絡的結構,還具有分析網絡中信息流動和傳播路徑的潛力。未來研究可以探索如何利用NSM數據追蹤信息在移民群體中的傳播軌跡,尤其是政策信息、健康知識等對移民生活產生重要影響的信息。這一分析對于理解移民群體的行為模式、信息獲取途徑和政策影響效應至關重要。例如,通過追蹤信息在社交網絡中的傳播路徑,研究者可以發現不同來源地移民群體在信息接收和擴散中的差異,幫助政府優化政策傳遞機制,確保重要信息能夠覆蓋到最需要的群體。
在全球化背景下,移民、難民及其他跨境群體的研究對全球政策制定者提出了新的挑戰。NSM方法憑借其靈活性和高效性,未來有望成為跨國移民研究中的標準工具。不同國家和地區的移民群體雖然具有獨特的文化背景和社交模式,但NSM方法能夠通過其逐步擴展的機制適應不同社會結構的變化。未來的跨國應用不僅能夠驗證NSM方法的廣泛適用性,還能夠為各國政府提供精細化、數據驅動的移民政策建議,推動全球范圍內的移民管理創新。
隨著NSM方法的應用范圍不斷擴大,未來的研究應考慮構建基于NSM數據的決策支持系統,為政府和相關機構提供實時的數據分析和預測工具。這一系統不僅可以用于跟蹤移民群體的社交動態,還可以用于模擬不同政策措施的潛在影響。例如,政府可以通過該系統提前預判某項政策在移民群體中的反應,預測政策執行后可能產生的社會影響,并通過實時數據調整決策方案。這樣的系統將推動政策制定從經驗驅動向數據驅動轉變,顯著提高政策的科學性和執行效率。
(四)結論
網絡記憶采樣(NSM)方法作為一種創新的鏈式采樣技術,已經在處理隱性群體、揭示復雜社交網絡以及提高樣本代表性方面展現了其巨大的潛力。未來,隨著技術的進步與研究的深入,NSM方法不僅將在移民研究中繼續發揮重要作用,還將為其他社會群體的研究提供新的可能性。
本研究對NSM方法在加拿大華人移民調查中的應用進行了系統論證,并通過對社交網絡的逐步揭示,解決了傳統采樣方法中的多個難題。未來,隨著人工智能、數據分析技術的結合與跨國研究的拓展,NSM方法的應用領域將進一步擴大,不僅限于移民研究,還將擴展至其他難以接觸的隱性群體研究,如難民、無家可歸者、非法勞工等。
此外,NSM方法的多維度分析能力將繼續優化,通過結合不同社會網絡層次、職業網絡與社區關系的交叉分析,未來的研究有望揭示更為復雜的群體互動與動態。隨著社交網絡分析工具和大數據技術的發展,NSM的采樣效率、數據處理能力以及樣本質量都將進一步提升。
總而言之,NSM方法不僅為社會科學研究帶來了新的視角與工具,還在全球化和復雜社會結構背景下,為隱性群體的研究提供了更加準確和廣泛的數據支持。未來,通過進一步優化該方法的操作流程、結合更多的技術創新,NSM將有能力成為社會研究中標準化的采樣工具,為政策制定者和學術界提供深刻的洞察與數據支持。
參考文獻
[1]Agans R P, Zeng D, Shook-Sa B E, et al. Using social networks to supplement RDD telephone surveys to oversample hard-to-reach populations: a new RDD+ RDS approach[J]. Sociological methodology, 2021, 51(2): 270-289.
[2]Avin C, Krishnamachari B. The power of choice in random walks: An empirical study[J]. Computer Networks, 2008, 52(1): 44-60.
[3]Beauchemin C, Hamel C, Simon P. Trajectoires et origines: enquête sur la diversité des populations en France[M]. Ined éditions, 2016.
[4]Lu X. Respondent-driven sampling: theory, limitations & improvements[M]. Karolinska Institutet (Sweden), 2013.
[5]Marpsat M, Razafindratsima N. Les méthodes d'enquêtes auprès des populations difficiles à joindre: Introduction au numéro spécial[J]. Methodological Innovations Online, 2010, 5(2): 3-16.
[6]Mercer S. Social network analysis and complex dynamic systems[J]. Motivational dynamics in language learning, 2015: 73-82.
[7]Mouw T, Verdery A M. Network sampling with memory: a proposal for more efficient sampling from social networks[J]. Sociological methodology, 2012, 42(1): 206-256.
[8]Portes A, Rumbaut R G. Immigrant America: a portrait[M]. Univ of California Press, 2024.
[9]Salganik M J. Bit by bit: Social research in the digital age[M]. Princeton University Press, 2019.
[10]Santos A, Charrance G. From theory to practice: Lessons learned from implementing the network sampling with memory method[C]//Proceedings of Statistics Canada Symposium 2022: Data Disaggregation: Building a More Representative Data Portrait of Society. Statistics Canada, 2024.
[11]Schiltz M A. Faire et défaire des groupes: l’information chiffrée sur les ?populations difficiles à atteindre?[J]. Bulletin de méthodologie sociologique. Bulletin of sociological methodology, 2005 (86): 30-54.
[12]Statistics Canada. 2021 Census of population [EB/OL]. Government of Canada, [2024-09-05]. https://www12.statcan.gc.ca/census-recensement/2021/dp-pd/index-eng.cfm.
作者信息(Author Biography):孫鵬(1982.10),博士,加拿大籍華人學者,研華學思特聘專家,專注于跨文化與全球化、文化與社會、人口與移民以及人才與教育等領域研究。他的研究興趣廣泛且深入,涵蓋了企業跨文化管理、全球化進程對企業和社會的影響、多元文化背景下的文化融合與沖突、國際移民與人口流動、國際人才交流以及華人社群和留學生問題等方面。孫鵬致力于探索企業在全球化背景下如何實現有效的跨文化管理,研究文化在全球化進程中的傳播與變遷,以及移民和人口流動對全球社會經濟的影響。同時,他也關注數字化轉型、技術創新與創業、環境保護與可持續發展等新興研究領域,力求通過多學科的視角,為社會和經濟的未來發展提供有力的理論支持和實踐指導。
本文為澎湃號作者或機構在澎湃新聞上傳并發布,僅代表該作者或機構觀點,不代表澎湃新聞的觀點或立場,澎湃新聞僅提供信息發布平臺。申請澎湃號請用電腦訪問http://renzheng.thepaper.cn。



- 報料熱線: 021-962866
- 報料郵箱: news@thepaper.cn
互聯網新聞信息服務許可證:31120170006
增值電信業務經營許可證:滬B2-2017116
? 2014-2025 上海東方報業有限公司

